본 게시글은 Onur Mutlu 교수의 유튜브 채널에 게시된 강의를 토대로 작성되었습니다.
https://www.youtube.com/c/OnurMutluLectures
Onur Mutlu Lectures
This channel contains videos and slides from courses taught and lectures delivered by Professor Onur Mutlu (https://people.inf.ethz.ch/omutlu/). Onur Mutlu is a Professor of Computer Science at ETH Zurich. He is also a faculty member at Carnegie Mellon Uni
www.youtube.com
Computer Architecture 분야의 대가이신 분입니다. 스터디카페에 편하게 앉아서 ETH Zurich에서 개설된 강의를 무료로 들을 수 있다니... 정말 좋은 세상입니다.
비교적 minor한 분야인 parallel processor의 고퀄리티 강의를 강의자료까지 무료로 제공해주셔서 정말 감사하게 생각합니다.
1. Taxonomy of Computers
2. Data Parallelism - How to Exploit Parallelism?
2-1. Data Parallelism
말 그대로 data를 병렬적으로(Parallelly) 처리하는 방식입니다. SISD의 Sequential하게 data를 처리하는 방식과 상반되는 방식이죠.
Data Parallelism도 다음과 같이 Concurrency가 언제 발생하냐를 기준으로 여러 단계로 분류할 수 있습니다.
Concurrency arises from
- Performing the same operation on different data하나의 operation(by instruction)을 처리할 때 여러 data를 사용하는 방식으로 Operation level parallelism이라고 합니다.SIMD가 이에 해당하며 본 게시물에서 주로 다루는 Parallelism level입니다.
- Execution different operations in paralleltask level parallelism이라고 하며 서로 다른 operation을 병렬적으로 처리하는 Parallelism level입니다.
- Execution different threads of control in parallel다른 threads들을 병렬적으로 처리하는 방식입니다. 아직 명확하게 이해하지 못했고 GPU 파트에서 등장할 예정입니다.
SIMD는 Operation level parallelism을 구현한 Computing이며 여러 개의 다른 data를 하나의 instruction으로 처리할 수 있습니다.
2-2. Vector processor vs Array processor
SIMD Processing은 두 가지 관점에서 기술할 수 있습니다.
하나는 In space parallelism이고 다른 하나는 In time parallelism입니다.
여기서 말하는 space란 Processing Elements(PEs로 표현하겠습니다.)을 말합니다.
In space 측면에서의 병렬성은 여러 개의 다른 space(PEs)를 사용하여 여러 개의 data를 동시에 처리하는 방식입니다.
이 In space에 해당하는 processor가 Vector processor입니다.
그리고 In time 측면에서의 병렬성은 하나의 space(PE)를 사용하여 연속적인 time steps안에서 여러 개의 data를 동시에 처리하는 방식입니다. 눈치 빠르신분들은 아셨겠지만 pipeline이 등장하는 개념입니다.
하지만 SISD CPU처럼 instruction level로 stage가 나뉘는 pipeline이 아닌 data element별로 stage가 나뉘는 pipeline입니다.(본문에서 data pipeline이라고 부르겠습니다.) 즉 매 clock cycle마다 multiple data element 중 하나의 data를 execution unit에 가져와서 operating할 수 있는 방식입니다.
이 In time에 해당하는 processor가 Array processor입니다.
이해를 돕기위해 Time-Space에 따른 diagram을 보겠습니다.
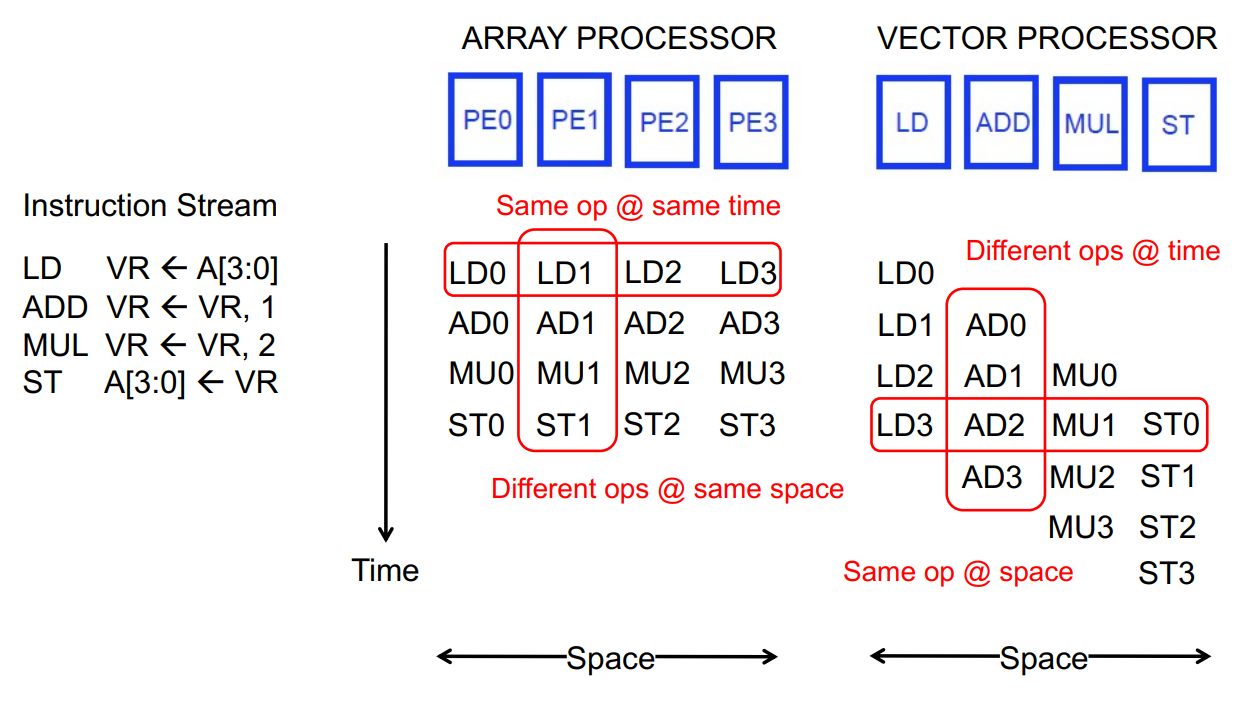
Instruction Stream을 보면 간단한 4개의 instruction을 확인할 수 있습니다. VR은 vector registesr의 약자로 뒤에서 설명하겠습니다.
element가 4개인 vector A를 VR에 load하고, VR에 저장된 A의 각각 element에 1씩 더하고 2를 곱하고
다시 A에 저장하는 명령어 입니다.
왼쪽의 Array processor의 동작을 보시면 매 cycle마다 mutiple element에 대해 instruction을 수행하는 모습을 볼 수 있습니다. 마치 SISD의 single cycle같이 직관적으로 이해할 수 있습니다.
Array processor의 경우 같은 시간축에서는 같은 operation을 수행하고, 같은 공간축에서는 각 PE가 서로 다른 operation을 수행합니다.
반면 오른쪽의 Vector processor의 동작을 보시면 매 clock cycle마다 multiple element의 each data에 대해 instruction을 수행하는 모습을 볼 수 있습니다.
Clock Cycle 1 : load A[0]
Clock Cycle 2 : load A[1] add A[0], 1
Clock Cycle 3 : load A[2] add A[1], 1 mul A[0], 2
Clock Cycle 4 : load A[3] add A[2], 1 mul A[1], 2 store A[0]
Clock Cycle 5 : add A[3], 1 mul A[2], 2 store A[1]
Clock Cycle 6 : mul A[3], 2 store A[2]
Clock Cycle 7 : store A[3]
위와 같이 매 cycle마다 vector의 element를 하나씩 처리하는 것을 볼 수 있습니다. 이는 뒤에서 설명할 Vector processor의 장점에서도 서술하는데 마치 CPU pipeline에서 Data forwarding을 하는 것 처럼 Data간의 Independency를 보장할 수 있습니다.
3. Vector processor
3-1. Vector processor overview
우선 vector라는 data structure을 정의하고 가겠습니다.
Vector processor에서 다루는 vector는 one-dimensional array of numbers입니다. 기존에 알고있던 vector와 크게 다른 점은 없습니다.
Vector를 다루기 위해서 다음이 필요합니다.
- Need to Load/Store Vector ➡ vector를 저장하는 vector register가 있습니다.
- Need to operate on vectors of different lengths ➡ vector length register(VLEN)가 존재합니다.
- Elements of a vector might be stored apart from each other in memory 즉, vector의 element들이 떨어져서 memory에 저장되어야 합니다.➡ vector stride register(VSTR)이 존재합니다. Stride를 사용해 vector of memory에 접근할 수 있습니다.
이때 Stride는 vector의 두 element 사이의 거리(address 관점에서 거리)를 의미합니다.
3-2. Simple Example - iteration without branch & Matrix multiply
예시를 통해 vector processor의 동작을 이해해봅시다.
다음과 같은 simple iteration을 고려해봅시다.
for (i = 1; i < 50; i++)
C[i] = (A[i] + B[i]) / 2SISD processor로 처리하려면 50 clock cycle이 필요하며 다량의 branch 명령이 발생합니다.
SIMD processor로 이 iteration을 처리한다면?
vector lengh는 50이고 4 PEs를 사용해 처리한다고 가정해봅시다.
그럼 매 clock cycle마다 4 element를 처리할 수 있으므로 약 13 clock cycle에 처리가능합니다. 즉, PEs에 operand를 넣는 작업(강의에서 feeding이라고 표현합니다.)을 13번 반복하면 더 빠르고 branch 명령없이 처리할 수 있습니다.
그 다음 Vector Stride를 이해하기 위한 예시를 봅시다.

위 그림은 간단한 Matrix Multiply를 나타낸 그림입니다.
4x6 matrix인 A와 6x10 matrix인 B를 곱하는 상황을 고려해봅시다.
이때 vector는 row를 기준으로 memory에 Linear address로 저장되어 있습니다. 즉, 첫번째 row부터 (0, 0), (0, 1), ... , (0, 5) 순서로 memory에 저장되어 있습니다.
vector A에 접근하는 것은 크게 어려운 점이 없습니다. element에 접근한뒤 address를 1늘리면 다음 element에 접근할 수 있기 때문입니다. 이때 vector A의 stride는 1입니다.
vector B에 접근할 때는 address 계산을 고려해줘야 합니다. column을 기준으로 연산하지만 memory는 row 기준으로 저장되어 있기 때문입니다. 그래서 element에 접근한뒤 vector length인 10을 current address에 더해줘야 다음 element에 접근할 수 있습니다. 이때 vector B의 stride는 10입니다.
Stride가 이해되시나요? Stride는 memory access instruction(vector load, vector store)에서 가져올 수 있습니다.
이때 element의 주소를 계산하는 부분을 LSU(Load Store Unit)이라고 부르는데 뒤에서 설명하겠습니다.
3-3. Advantage & Disadvantage
Vector processor의 advantage와 disadvantage입니다.
- Advantage
- No dependencies within a vectorPipelining과 parallelization이 상당히 잘 작동합니다.Dependency가 생기지 않아서 deep pipeline을 구현할 수 있습니다.
- Each instruction generates a lot of work하나의 instruction으로 대량의 data를 처리할 수 있으므로 Instruction fetch에 필요한 bandwidth를 줄일 수 있습니다.Memory access instruction은 Computing instruction보다 상당히 cost(clock cycle, power)가 높은 instruction이라서 줄일 수록 좋습니다.
- No need to explicitly code loopsVector 단위로 연산할 수 있기 때문에 Loop code가 있더라도 branch instruction을 거의 사용하지 않습니다.
- Highly regular memory access pattern Stride를 사용하면 regular한 memory access pattern이 나타납니다.
- Disadvantage
- Work (only) if parallelism is regular i.e., Very inefficient if parallelism is irregular당연한 얘기지만 vector, matrix와 같이 regular한 자료구조가 아니라면 성능이 급격히 떨어집니다.또는 irregular한 control flow가 있는 경우(빈번한 branch, jump)에도 성능이 급격히 떨어집니다.
- Vector processor has to obey amdahl's law암달의 법칙에 따라 serial execution의 비중이 높아지면 speedup이 제한됩니다. 이를 Serial bottleneck이라고 합니다.
- Memory can easily become a bottleneck especially if
- compute/memory operation balance is not maintained
- data is not mapped appropriately to memory banks이러한 bottleneck이 Real world workload에서 매우 빈번하게 발생합니다.
3-4. Vector Register(VR)
Vector register는 말 그대로 vector를 저장하는 register입니다. 각각의 vector regiter는 N개의 M-bit values를 저장합니다.
그리고 Vector control register에는 VLEN(vector length register), VSTR(vector stride register), VMASK가 있습니다. VMASK는 뒤에서 서술하겠습니다.
VLEN은 최대 N이 될 수 있습니다. N이 vector register에 저장될 수 있는 element의 최대 개수를 의미합니다.

3-5. Vector Functional Units(VFU)
fast clock cycle내에 element operation을 수행하기 위해 deep pipeline을 사용합니다.
pipeline이 깊어져도 Control flow는 의외로 간단합니다. vector의 element들이 independent해서 Hazard가 발생하지 않기 때문입니다.
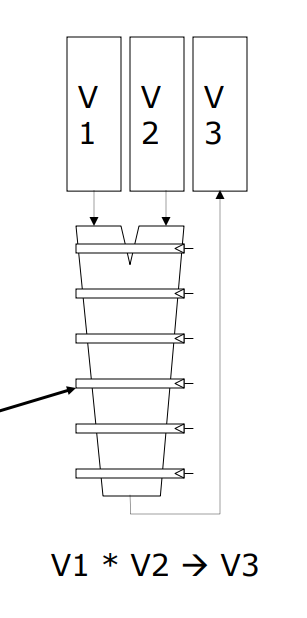
오른쪽 그림은 6 stage pipeline을 사용하는 VFU입니다. 각 stage별로 v1, v2의 element를 연산해서 VR v3에 저장합니다.
이때 같은 instruction을 다른 pipeline에 동시에 수행하는 것을 고려할 수 있습니다.
이렇게 2가지 병렬성(Parallelism in time & space)을 동시에 구현해 Vector processor와 Array processor를 결합하는 설계 방법도 있습니다.
본 강의를 들으면서 verilog로 짜볼 생각입니다.
'EE > Parallel Computer Architecture' 카테고리의 다른 글
| [Parallel Computer archi] (0) | 2023.04.12 |
|---|---|
| [Parallel Computer Architecture] Fine-Grained Multithreading (0) | 2022.07.17 |
| [Parallel Computer Architecture] Combination of Vector & Array processor (0) | 2022.07.16 |
| [Parallel Computer Architecture] Memory access of vector processor (0) | 2022.07.16 |