본 게시글은 Onur Mutlu 교수의 유튜브 채널에 게시된 강의를 토대로 작성되었습니다.
https://www.youtube.com/c/OnurMutluLectures
Onur Mutlu Lectures
This channel contains videos and slides from courses taught and lectures delivered by Professor Onur Mutlu (https://people.inf.ethz.ch/omutlu/). Onur Mutlu is a Professor of Computer Science at ETH Zurich. He is also a faculty member at Carnegie Mellon Uni
www.youtube.com
1. Is there any point in distinguishing Vector & Array processor?
첫 게시글에서도 봤듯이, 두 processor는 data level parallelism을 어떤 방식으로 구현하냐에 따라 구별할 수 있습니다.
그렇다면 Vector processor와 Array processor를 구별하는게 과연 의미가 있는 걸까요?
본 강의에서는 두 processor의 구별이 purist's distinction이라고 표현합니다. 그저 구별을 위한 구별일 뿐이라는 말입니다.
결국 SIMD processor는 두 가지 parallelism 구현 방식을 모두 채택해야 합니다. Processing Element(PE)를 여러 개 가지면서, 각 PE는 data element를 pipeline으로 처리해야 하죠. GPU가 이 두 가지 data level parallelism을 구현한 대표적인 예시입니다.
2. Combination of Both - Modern SIMD processor
2-1. Example of combination - Execution unit
element per vector = 28인 vector를 연산하는 상황을 예시로 보겠습니다.

왼쪽은 lane이 1개인 Vector processor입니다. number of lanes = 1 이므로 1 cycle당 한 번의 연산을 수행합니다.
반면 오른쪽은 number of lanes = 4인 Vector와 Array를 합친 processor입니다. data element의 순서대로 4개의 element를 4개의 lane에서 병렬적으로 연산합니다.
이때 각각의 lane을 따로 봅시다.
첫 번째 lane은 element index % 4 == 0을 만족하는 data element을 처리합니다.
두 번째 lane은 element index % 4 == 1
세 번째 lane은 element index % 4 == 2
네 번째 lane은 element index % 4 == 3
을 각각 만족하는 data element를 처리합니다.
이때 number of lane에 따라서 처리하는 data element의 index도 달라질 수 있습니다.
2-2. Processor level - Set of SIMD engines
위 그림은 Execution unit에 대해서 고려한 것이고, Processor level에서 위 상황을 고려해보겠습니다.
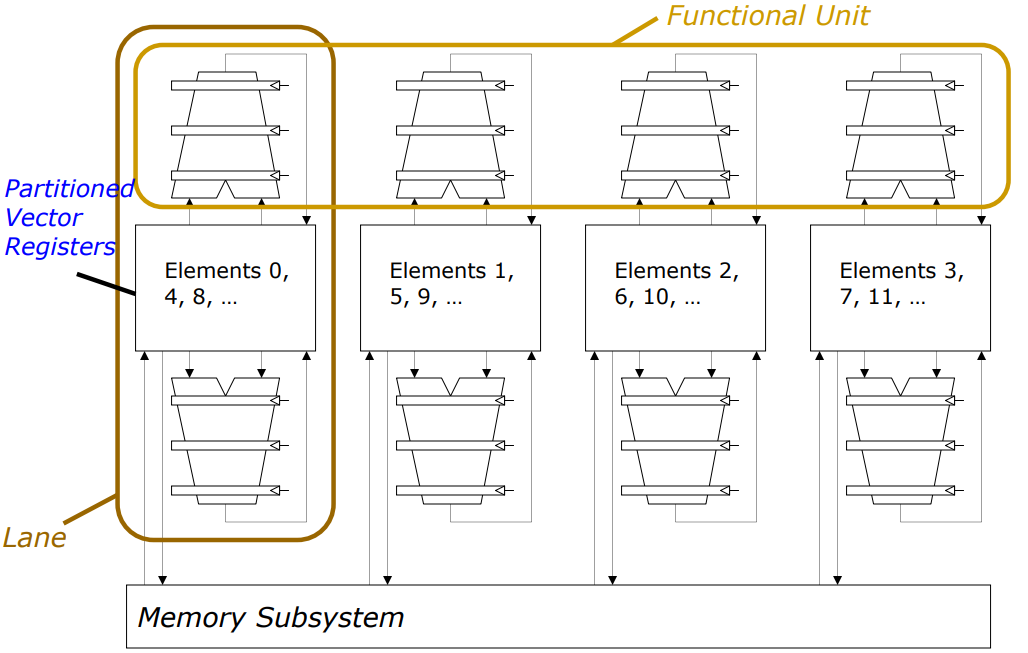
2-1에서와 같이 number of lane = 4인 case입니다.
논문, textbook 별로 용어가 다르지만, 본 게시글에서는 각 lane을 SIMD engine이라고 부르겠습니다.
2-1에서 봤듯이 각 SIMD engine은 index % 4의 값에 따른 index를 가지는 element를 처리합니다. 각각 Register와 Execution unit, Load/Store unit을 가지며, Shared memory와 interconnect되어 있습니다.
위와 같은 SIMD processor의 동작을 추상화시켜서 확인해보겠습니다.

예시와는 다르게 elements per vector = 32이고 number of lanes = 8인 case입니다.
각각의 시간 단위(편의상 1 clock cycle로 가정)마다, 8개 Unit들(Load, Multiply, Add)이 병렬적으로 동작하는 것을 볼 수 있습니다.
1 clock cycle Load A[ 0 ] ~ A[ 7 ]
2 clock cycle Load A[ 8 ] ~ A[15] Mul A[ 0 ] ~ A[ 7 ]
3 clock cycle Load A[16] ~ A[23] Mul A[ 8 ] ~ A[15] Add A[ 0 ] ~ Add A[ 7 ]
4 clock cycle Load A[24] ~ A[31] Mul A[16] ~ A[23] Add A[ 8 ] ~ Add A[15]
5 clock cycle Load B[ 0 ] ~ B[ 7 ] Mul A[24] ~ A[31] Add A[16] ~ Add A[23]
6 clock cycle Load B[ 8 ] ~ B[15] Mul B[ 0 ] ~ B[ 7 ] Add A[24] ~ Add A[31]
7 clock cycle Load B[16] ~ B[23] Mul B[ 8 ] ~ B[15] Add B[ 0 ] ~ Add B[ 7 ]
8 clock cycle Load B[24] ~ B[31] Mul B[16] ~ B[23] Add B[ 8 ] ~ Add B[15]
9 clock cycle Mul B[24] ~ B[31] Add B[16] ~ Add B[23]
10 clock cycle Add B[24] ~ Add B[31]
위 표와 같이 8개의 lane에서 병렬적으로 연산을 수행함과 동시에 data level pipelining도 함께 진행되는 것을 볼 수 있습니다.
2-3. Atomic Code Vectorization
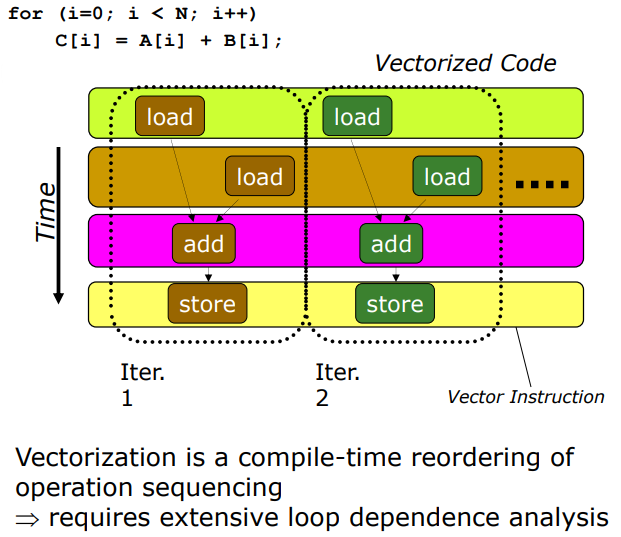
위 그림의 for문을 수행할 때 Compiler가 operation sequence를 reordering해줍니다. 그럼 branch instruction없이 for loop를 처리할 수 있는데 이럼 Vectorization이라고 합니다.
하지만 loop간에 dependency를 확인하는데 많은 cost가 소모됩니다.
'EE > Parallel Computer Architecture' 카테고리의 다른 글
| [Parallel Computer archi] (0) | 2023.04.12 |
|---|---|
| [Parallel Computer Architecture] Fine-Grained Multithreading (0) | 2022.07.17 |
| [Parallel Computer Architecture] Memory access of vector processor (0) | 2022.07.16 |
| [Parallel Computer Architecture] SIMD Processors (0) | 2022.07.10 |