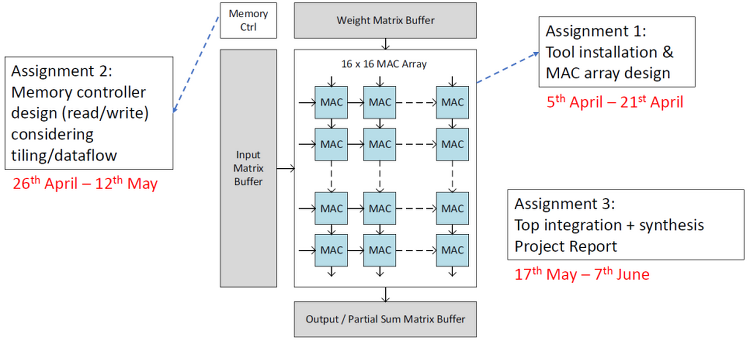
[AI Silicon System] 게시물은 KAIST 김주영 교수님의 강의자료와 Project document를 참고하여 작성하였습니다. 첫 번째 Project입니다. 16 X 16 MAC array를 설계하면 됩니다. 이 단계에서는 Memory control은 고려하지 않아도 되고, tb에서 MAC array에 맞게 data를 feeding 해줍니다. 1. Objective Implement a systolic MAC array datapath Compute matrix multiplication using MAC arry 2. Specification Input feature map bit-width: 16 bit Weight bit-width: 8 bit Output feature map ..